Processor companies are significantly enhancing AI development by integrating robust software support, enabling more efficient and scalable AI solutions. This strategic shift allows for better optimization of AI workloads, improved performance, and accelerated deployment across various industries.
What Strategies Are Processor Companies Employing to Support AI Development?
Processor companies are adopting several strategies to bolster AI development:
-
Integrated Software Frameworks: Companies like Arm, Intel, and NXP are developing hardware-integrated frameworks to optimize AI performance and resource efficiency.
-
In-House Innovation: Intel is focusing on evolving its existing products to meet new AI trends, such as robotics and autonomous agents, by revamping its design philosophy and aligning closely with customer needs.
-
Open-Source Platforms: Nvidia has launched Dynamo, an open-source inference platform, to provide developers with more flexible and efficient tools for AI model deployment.
How Are These Strategies Impacting AI Development?
The integration of software support by processor companies is leading to:
-
Enhanced Performance: Optimized software frameworks allow for better utilization of hardware capabilities, resulting in faster and more efficient AI computations.
-
Scalability: Software support enables AI solutions to scale more effectively across different platforms and devices.
-
Accelerated Deployment: Developers can bring AI applications to market more quickly due to streamlined development processes and tools.
What Are the Challenges Faced by Processor Companies in Supporting AI Development?
Despite the advancements, processor companies encounter several challenges:
-
Competition: Nvidia’s dominance in the AI chip market presents a significant hurdle for other companies attempting to gain market share.
-
Technological Complexity: Developing integrated software frameworks that effectively leverage hardware capabilities requires significant investment and expertise.
-
Market Adoption: Encouraging widespread adoption of new software platforms can be difficult, especially when competing against established ecosystems.
Buying Tips
When considering AI development solutions, it’s essential to evaluate both hardware and software offerings from processor companies. Look for integrated frameworks that provide optimized performance and scalability. Assess the level of support and community engagement for the software platforms to ensure long-term viability.
As a reliable Electronic Components Source, Fly-Wing Technology (HK) Co., Limited has been consistently dedicated to assisting customers in finding hard-to-find parts quickly and accurately, as well as acquiring new and original parts at competitive prices since 2012. Our optimized in-stock inventory and global supplier network reduce procurement cycles, lower transaction costs, and provide quality electronic components at competitive prices.
Electronic Components Expert Views
“The integration of software support by processor companies is a game-changer in AI development. It allows for more efficient use of hardware resources and accelerates the deployment of AI applications across various industries.”
FAQ
Q: Why is software support important in AI development?
A: Software support enables better optimization of hardware capabilities, leading to improved performance and scalability of AI applications.
Q: Which processor companies are leading in AI software support?
A: Companies like Arm, Intel, and Nvidia are at the forefront, developing integrated frameworks and platforms to enhance AI development.
Q: What challenges do processor companies face in supporting AI development?
A: They face competition from established players, technological complexities in developing integrated frameworks, and challenges in achieving widespread market adoption.
Arm, Intel, and NXP are lending their hands to the software world with new hardware-integrated frameworks.
In today’s competitive landscape of artificial intelligence, software tools have become just as crucial as hardware. Companies are increasingly utilizing frameworks designed to optimize performance and enhance resource efficiency, effectively bridging the gap between complex models and end devices.
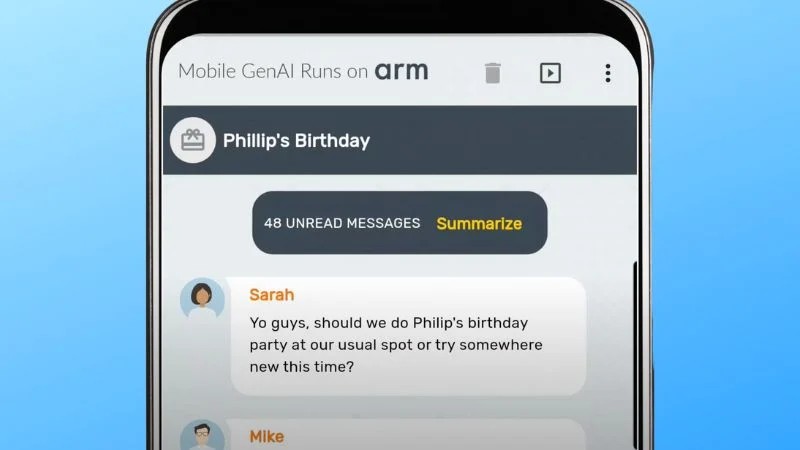
Arm believes the ExecuTorch collaboration may bring many benefits to generative AI applications. Screenshot (modified) used courtesy of Arm
Recently, processor manufacturers have begun to go beyond traditional hardware offerings to facilitate smoother workflows for developers. They are creating tool ecosystems that seamlessly integrate with existing systems. In this article, we will explore some of the most significant software advancements from the industry’s leading hardware providers, including Arm, NXP, and Intel.
Arm’s ExecuTorch Beta Release
Arm has recently partnered with Meta to optimize AI applications for edge devices using the ExecuTorch framework. Designed for Arm’s widely adopted mobile and IoT processors, this PyTorch-native framework now supports highly compact, quantized models, including Meta’s Llama 3.2.
By utilizing the Arm KleidiAI library, ExecuTorch takes advantage of low-bit matrix multiplication micro-kernels through the XNNPACK backend. Arm claims that ExecuTorch can enhance on-device inference speeds by up to 20% on Arm Cortex-A v9 CPUs. Additionally, it employs a four-bit quantization scheme that improves model efficiency by balancing accuracy with reduced bit requirements. With this integration, the quantized Llama 3.2 model can achieve over 400 tokens per second during the prefill stage on mobile devices such as the Samsung S24+.
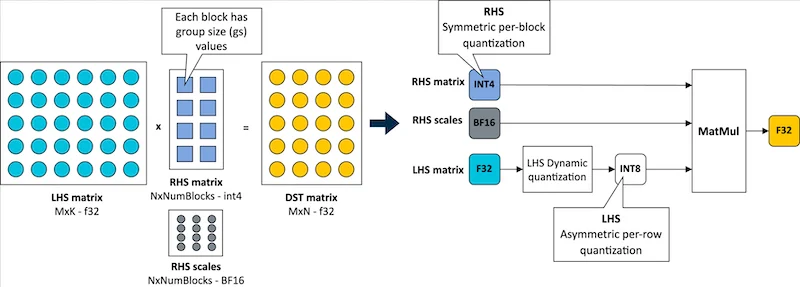
Four-bit quantization with a per-block strategy for weights and per-row quantization for activations
ExecuTorch’s architecture streamlines model deployment by eliminating the need for model conversion, thereby simplifying the developer workflow and directly enhancing performance on Arm-based devices. This configuration delivers a twofold improvement in decoding speed and a fivefold increase in prefill performance. For instance, the collaboration showcased a reduced Llama 3.2 model size of 1.1 GiB compared to 2.3 GiB for traditional BF16 formats, along with a 40% reduction in runtime memory requirements.
NXP’s eIQ Software Expansion
NXP Semiconductors has recently introduced the eIQ Time Series Studio as part of its enhanced eIQ AI software suite. This tool features an automated machine-learning workflow that accelerates model creation and deployment across MCU and application processor platforms. Specifically designed to handle complex time series data from temperature, voltage, and pressure sensors, the eIQ Time Series Studio enables users to develop models for anomaly detection, classification, and regression.
The tool incorporates advanced data curation and preprocessing capabilities to optimize raw sequential data, ensuring model precision while efficiently managing memory and storage requirements for resource-constrained devices.
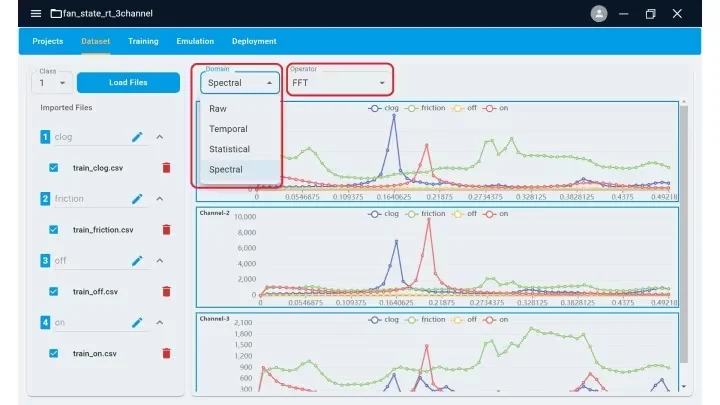
The data input page of eIQ
Additionally, eIQ Time Series Studio offers developers features such as model auto-generation, optimization, and emulation, transforming traditional iterative workflows into rapid one-click operations. With the platform’s emulation capabilities, developers can validate model performance in a simulated edge environment that closely mimics actual hardware deployment conditions. The streamlined deployment process is compatible with NXP’s MCUXpresso and CodeWarrior IDEs, enabling seamless integration with MCU libraries through simple API calls.
Complementing the Time Series Studio, NXP’s GenAI Flow introduces generative AI capabilities with retrieval-augmented generation (RAG) fine-tuning. This allows users to customize large language models (LLMs) for specific edge use cases. Designed for the i.MX applications processor family, this tool facilitates model customization by training LLMs on domain-specific data while ensuring data privacy is maintained.
Intel’s PyTorch 2.5 Contributions
Recently, Intel expanded support for Intel GPUs in PyTorch 2.5, specifically for the Intel Arc discrete graphics and the Intel Data Center GPU Max Series. The company has integrated SYCL kernels to enhance Aten operator support, which will significantly boost performance in PyTorch’s eager mode, enabling faster and more efficient model training.
In addition, Intel has refined the torch.compile backend for Intel GPUs, improving both inference and training performance for deep learning workloads. The latest PyTorch release also upgrades the FP16 datatype for Intel’s data center CPUs, utilizing Intel Advanced Matrix Extensions to enhance inference speed and efficiency in both eager mode and TorchInductor.
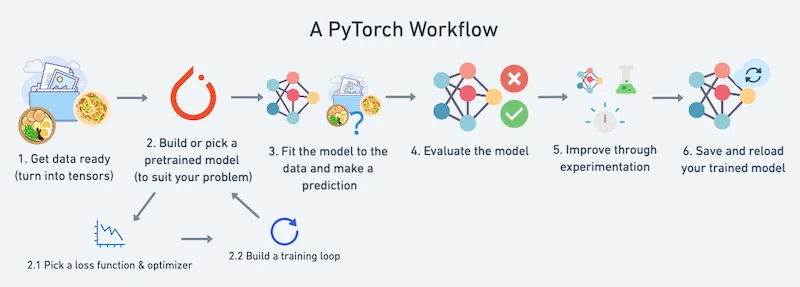
A PyTorch workflow
The release also includes the TorchInductor C++ backend for Windows, offering developers a streamlined experience on Windows-based systems.
Hardware-Integrated Frameworks
As AI becomes increasingly essential across mobile, IoT, and edge platforms, the tools discussed in this article indicate a shift toward cohesive, hardware-integrated frameworks that streamline model deployment. By aligning software advancements with processor architectures, companies like Arm, NXP, and Intel are enabling the development of more efficient and capable AI models within constrained hardware environments. This convergence of hardware and software is likely to pave the way for more powerful edge applications, reduce barriers for developers, and accelerate the adoption of AI solutions across diverse sectors.